About the Data
Data
This project used three publicly available datasets.
The dataset chosen to show the average years of education by country was a dataset from Our World Data called "average years of schooling" (average-years-of-schooling-among-adults.csv).
The dataset chosen to show income data was titled "adjusted net national income per capita" (API_NY.ADJ.NNTY.PC.CD_DS2_en_csv_v2_7997.csv) from the World Bank Group.
The third dataset called "world countries generalized" (World_Countries_(Generalized)_9029012925078512962.geojson) was from ArcGIS Hub,
and was chosen for country shapes and for merging to the other datasets.
The year range chosen was from 2000 to 2021 as it was the greatest range of data that was able to avoid the following problem:
earlier and later data had incomplete entries or different numbers of countries which is not ideal when merging the initial schooling (education) and income data to the countries dataset.
These datasets were chosen as they were easy to work with and contained sufficient data, specifically for country names as the data file for the countries from arcgis had 252 countries,
and we wanted the data to have the same number of rows (or at least not missing too many countries) when being merged to the countries dataset.
Data Cleaning Choices and Results
Education Dataset (Average Years of Schooling Among Adults):
The original dataset “average-years-of-schooling-among-adults.csv” originally contained the following columns:
Entity (country name), Code (three-character abbreviation of the country), Year (1960-2023), and Both genders (average years of schooling for both genders combined).
Income Dataset (Adjusted Net National Income Per Capita (Current US$)):
The original dataset “API_NY.ADJ.NNTY.PC.CD_DS2_en_csv_v2_7997.csv” originally contained the following columns:
Country Name, Country Code (three-character abbreviation of the country), Indicator Name (Adjusted net national income per capita (current US$)),
Indicator Code (abbreviation of indicator name), and year columns 1960-2024.
It also has the first four rows showing Data Source and Last Updated Date (we cut out those 4 rows when loading data for cleaning).
World Countries Dataset (World Countries Generalized):
The original dataset “World_Countries_(Generalized)_9029012925078512962.geojson” originally contained the following columns:
FID, COUNTRY, ISO (two digit ISO code for the country), COUNTRYAFF (the parent country the country is affiliated with), AFF_ISO (the two digit ISO code of the parent country affiliated with the country),
and geometry (the polygon shape of the country).
Data Cleaning Choices
When cleaning the data we chose to keep only necessary columns, because there were many columns that were unncessary for the final visualization such as FID or ISO.
Cutting those excess columns out helps keep the data organized and clean.
Initially we cleaned and output three csv and three geojson files for each year, however later we realized it would be faster to just load everything from one data file
(aka "merged_YEAR.geojson") and that using additional data files would require additional resources on the user's side which is not ideal as it makes the experience worse for them
due to potential longer load times as more data is retrieved and loaded.
Dataset Columns per Dataset Kept After Merging and Cleaning
- merged_YEAR.csv (has no geometry column) and merged_YEAR.geojson contained the following columns and geojson properties: COUNTRY, geometry, INCOME, AVG_YR_SCH
- schooling_YEAR.csv (has no geometry column) and schooling_YEAR.geojson contained the following columns and geojson properties: COUNTRY, geometry, AVG_YR_SCH
- income_YEAR.csv (has no geometry column) and income_YEAR.geojson contained the following columns and geojson properties: COUNTRY, geometry, INCOME
File Structure
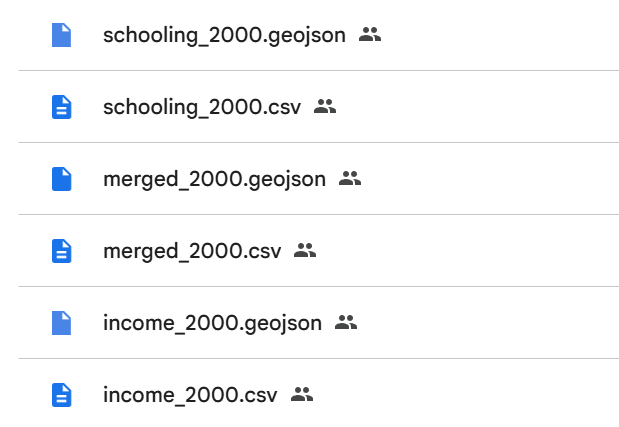
As a result of cleaning the data, the file structure ended up being as follows: assets/YEAR/(files for year, see image below)
The image above shows a screenshot from Google Drive of sample set of data files that can be found in a folder for a year of data. In this case the sample set is of data from the year 2000
Final Data Columns and Geojson Properties
- After cleaning the dataset, merged_YEAR.csv (has no geometry column) and merged_YEAR.geojson contained the following columns and geojson properties: COUNTRY, INCOME, AVG_YR_SCH, geometry
COUNTRY - country name
INCOME - adjusted net national income per capita (current US$)
AVG_YR_SCH - average years of schooling among adults both genders
geometry - location and polygon shape
Data Cleaning Process and About Missing Data Values
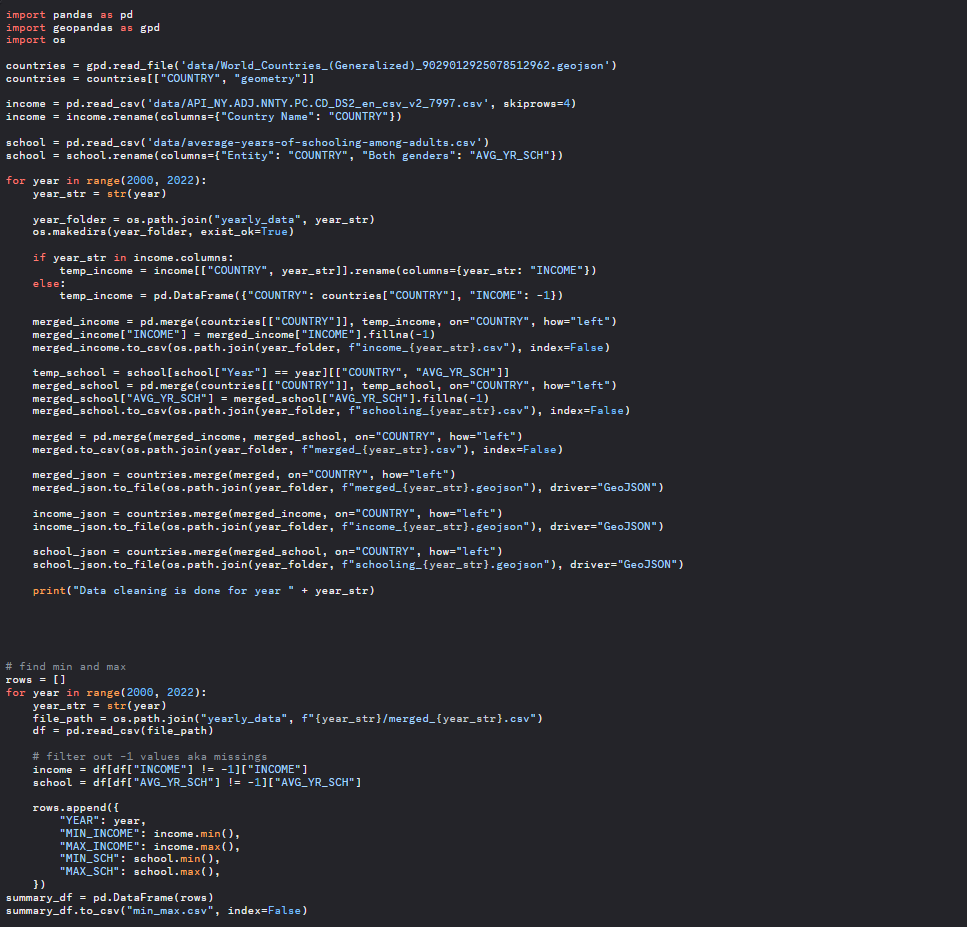
We used python for data cleaning as seen in the image below.
In short, the script standardizes column names, aligns all datasets by year, fills missing values, and outputs the results to cleaned GeoJSON files for each year.
If a value is missing from the dataset, we assign -1 to indicate missing data because it's much easier for the map and charts to process a real numeric value
than a blank cell or a string like "NaN". We opted not to use 0 for missing data because 0 could be interpreted as a meaningful value (e.g., zero income or zero years of schooling),
which would be misleading. These -1 values are shown as "No Data" in the maps.
View Data
Datasets Before Cleaning:
Average Years of Schooling Among Adults dataset from Our World in Data, which provides the average number of years adults aged 25 and older have spent in formal education: https://ourworldindata.org/grapher/years-of-schooling
Adjusted net national income per capita (current US$) from the World Bank Group, which provides comparable wage data (converted to USD using the 2024 rate) across many countries: https://data.worldbank.org/indicator/NY.ADJ.NNTY.PC.CD
World Countries Generalized from ArcGIS Hub for country shapes and for merging to datasets: https://hub.arcgis.com/datasets/esri::world-countries-generalized
Cleaned Data Folder:
Final Dataset Folder Post Cleaning Google Drive Link: https://drive.google.com/drive/folders/1dLkyqLmdP-t80cjHf4-kDiHQ1FnrYG1U?usp=drive_link